Let me describe the scenario:
- You have a linux software raid (raid5, in my case, created with mdadm).
- On top of it, you have a few LVM volumes, and LUKS encrypted partitions.
- You literally set this up 10 years ago - 4 disks 2 Tb each.
- It has been running strong for the last 10 years, with the occasional disk replaced.
- You just bought new 8Tb disks.
And now, you want to replace the old disks for the new ones, increase the size of the raid5 volume and, well, you want to do it live (with the partition in use, read write without unmounting it, and without rebooting the machine).
All of this with consumer hardware, that DOES NOT SUPPORT ANY SORT OF HOT SWAP. Basically, no hardware raid controller, just the cheapest SATA support offered by the cheapest atom motherboard that you bought 10 years ago that happened to have enough SATA plugs.
Not for the faint of hearts, but turns out this is possible with a stock linux kernel, fairly easy to do, and worked really well for me.
All you need to do is to make sure you type a few more commands from your shell, so that your incredibly cheap and naive SATA controller and linux system knows what you're up to before going around touching the wiring.
[ ... ]
Let's say you have a Carbon X1 5th gen.
Let's say your trackpoint is an TPPS/2 Elan TrackPoint
(and you can check this by running xinput |grep -i TrackPoint).
Let's say you have tried various xinput or /sys/.*/acceleration or
/sys/.*/speed settings. But still...
This is what fixed it for me:
-
Run:
mkdir -p /etc/libinput -
Create a
local-overrides.quirkfile with:cat > /etc/libinput/local-overrides.quirks <<END [Trackpoint Override] MatchUdevType=pointingstick AttrTrackpointMultiplier=2.0 END
-
Logout login / restart your X server / wayland.
-
Enjoy the increased speed! Increase the
2.0above for a faster experience, decrease it for a slower experience.
In one cuttable and pastable blob:
mkdir -p /etc/libinput cat > /etc/libinput/local-overrides.quirks <<END [Trackpoint Override] MatchUdevType=pointingstick AttrTrackpointMultiplier=2.0 END
In case this does not work, read on. I recommend you jump to the last section, and play with libinput debug-gui,
or libinput quirks list /dev/input/event2 or whatever your trackpad is associated with.
[ ... ]
When thiking about Docker and what it is designed to do, what comes to mind are disposable containers: containers that are instantiated as many times as necessary to run an application or to complete some work, to then be deleted as soon as the work is done or the application needs to be restarted.
It's what you do when you use a plain Dockerfile to package an application and all its dependencies into a container at build or release time, for example, to then instantiate (and delete) that container on your production machines (kubernetes?).
It's what you do when you compose one or more containers to create an hermetic environment for your build or test system to run on, with a new container instantiated for each run of your build or test, deleted as soon as the process has completed.
Over the last year, however, I learned to love to use docker for something it was not quite designed to do: persistent development environments.
Before attacking me violently for committing such a horrible sin, let me explain the use case first.
[ ... ]
When you run a an application under docker, you have a few different mechanisms you can choose from to provide networking connectivity.
This article digs into some of the details of two of the most common mechanisms, while trying to estimate the cost of each.
The most common way to provide network connectivity to a docker
container is to use the -p parameter to docker run. For
example, by running:
docker run --rm -d -p 10000:10000 envoyproxy/envoy
you have exposed port 10000 of an envoy container
on port 10000 of your host machine.
Let's see how this works. As root, from your host, run:
netstat -ntlp
and look for port 10000. You'll probably see something like:
[...] tcp6 0 0 :::10000 :::* LISTEN 31541/docker-proxy [...]
this means that port 10000 is open by a process called docker-proxy, not envoy.
Like the name implies, docker-proxy is a networking proxy
similar to many others: an userspace application that listens on
a port, forwarding bytes and connections back and forth as necessary.
[ ... ]
I recently had to increase the size of an encrypted partition on my
Debian server. I have been a long time user of LVM and dm-crypt
and tried similar processes in the early days of the technology.
I was really impressed by how easy it was today, and how it all just worked without effort without having to reboot the system, mark the filesystems read only, or unmount them.
Here are the steps I used, on a live system:
-
Used
mountto determine the name of the cleartext partition to resize. In my case, I wanted to add more space to/opt/media, so I run:# mount |grep /opt/media /dev/mapper/cleartext-media on /opt/media type ext4 (rw,nosuid,nodev,noexec,noatime,nodiratime,discard,errors=remount-ro,data=ordered)
which means that
/opt/mediais backed by/dev/mapper/cleartext-media -
Used
cryptsetupto determine the name of the encrypted Logical Volume backing the encrypted partition:# cryptsetup status /dev/mapper/cleartext-media /dev/mapper/cleartext-media is active and is in use. type: LUKS1 cipher: [...] keysize: [...] device: /dev/mapper/system-encrypted--media offset: 4096 sectors size: [...] sectors mode: read/write flags:
From this output, you can tell that
/dev/mapper/cleartext-mediais the cleartext version of the/dev/mapper/system-encrypted--media, wheresystemis the name of the Volume Group whileencrypted-mediais the name of the Logical Volume.
[ ... ]
When talking about using Debian, one of the first objections people will raise is the fact that it only has "old packages", it is not updated often enough.
This is generally not true. Or well, "true" if you stick to the "stable" release of Debian, which might not be the right version for you.
Also, people don't often realize that it's easy to use more than one "release"
on a given system. For example, you can configure apt-get to install "stable"
packages by defautl, but allow you to do a manual override to install from "testing"
or "unstable", or vice-versa.
Before starting, it's worth noting that this might not be for the faint of hearts: mixing and matching debian releases is generally risky and discouraged. Why is this a problem? Well, it all has to do with dependencies, backward compatibility and the fact that they may not always be correctly tracked.
For example: let's say you install a cool new gnome application from unstable. This
cool and new application depends on the latest icons, which apt also correctly installs.
Now, in the new icons package, some old icons have been removed. Old applications using
them will either need to be upgraded, or their icons break. This is generally handled
correctly by apt-get dependencies, assuming the maintainer did a really good job
tracking versions. But this is hard to do, and error prone at times.
Worst can happen with C libraries or different GCC versions using different ABIs, or
systemic changes like the introduction of systemd or similar.
[ ... ]
I have always heard that it was possible to guess the content of "HTTPS" requests based on traffic patterns. For example: a large long download from youtube.com, is, well, very likely to be a video :).
But how easy is it to go from a traffic dump, captured with something like tcpdump
to the list of pages visited by an user? Mind me: I'm talking about pages here - URLs, actual content.
Not just domain names.
Turns out it's not that hard. Or at least, I was able to do just that within a few tries. All you need to do is crawl web sites to build "indexes of fingerprints", and well, match them to the https traffic.
In this post, I'd like to show you how some properties of HTTPS can easily be exploited to see the pages you visited and violate your privacy - or track your behavior - without actually deciphering the traffic.
The post also describes a naive implementation of a fingerprinting and matching algorithm that I used on a few experiments to go from traffic dump, to the list of full URLs visited.
[ ... ]
Let's say you are thinking about moving to Rome in the near future.
Let's say you have family, and you want to find all daycares within 30 mins by public transport to your perspective new house.
Or maybe you want to find a house that's near a daycare, which in turn should be within 30 mins to your workplace.
In the past, I would have done this manually: find list of day cares, look at a map, check workplace, apartment, eventually find something that works.
But with a little javascript, some scripting skills, and a couple hours to spare, it turns out that this sort of problem is really easy to solve by using public APIs, and a little work.
Before I get started, and only if you are curious, you can see the outcome here http://rome.rabexc.org. The source code can also be found on github, in this repository.
This article can serve as a very quick start and brief introdcution to Google Maps APIs.
The first step for me was finding the data: the list of all daycares / pre-schools in Rome.
[ ... ]
Did you know that you can generate nicely formatted HTML file from your source code with clang?
I just noticed this by peeking in the source code, took me a few attempts to get the command line right, but here it is:
clang -S -Xclang -emit-html test.c -o test.html
Which will create a colorful and nicely formatted version of your .c file, which you can see here.
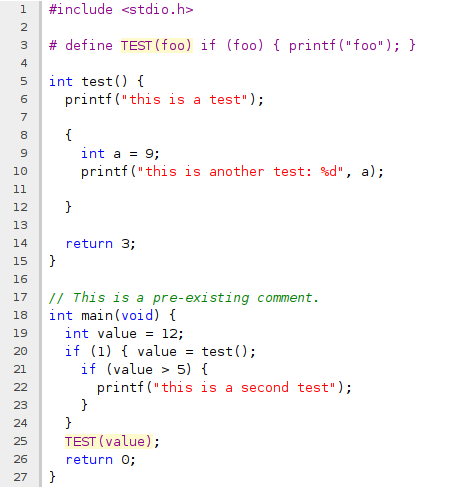
The only annoyance? Not surprisingly, it will fail if the file syntax is invalid, or it can't be parsed correctly. You should probably pass all the same options as if you were compiling it for real.
[ ... ]
Recently, I tried to run a Java application on my Debian workstation that needed to establish SSL / HTTPs connections.
But... as soon as a connection was attempted, the application failed with an ugly stack trace:
ValidatorException: No trusted certificate found sun.security.validator.ValidatorException: No trusted certificate found at net.filebot.web.WebRequest.fetch(WebRequest.java:123) at net.filebot.web.WebRequest.fetchIfModified(WebRequest.java:101) at net.filebot.web.CachedResource.fetchData(CachedResource.java:28) at net.filebot.web.CachedResource.fetchData(CachedResource.java:11) at net.filebot.web.AbstractCachedResource.fetch(AbstractCachedResource.java:137) at net.filebot.web.AbstractCachedResource.get(AbstractCachedResource.java:82) at net.filebot.cli.ArgumentProcessor$DefaultScriptProvider.fetchScript(ArgumentProcessor.java:210) at net.filebot.cli.ScriptShell.runScript(ScriptShell.java:82) at net.filebot.cli.ArgumentProcessor.process(ArgumentProcessor.java:116) at net.filebot.Main.main(Main.java:169) Failure (<C2><B0>_<C2><B0>)
First attempts at solving the problem were trivial: install all trusted SSL certificates on the Debian box.
[ ... ]
A bit more than a year ago I became the proud parent of the cutest little girl in the world.
By living abroad and traveling often, the little one had to endure quite a few trips with us on her first year: west to east coast and back, with a road trip involving New York and Boston, a few trips to Europe and one trip to Hawaii. All spiced up with hours of driving and a few rides on trains, buses and even trams.
In this blog post I'd like to tell you about our experience flying internationally with a baby: what worked, what didn't, and the lessons we have learned.
- Documents and paperwork
-
If you are traveling internationally, your baby needs his/her own passport.
Getting a passport is easy: bring a picture, birth certificate, your ID (passport, in state driving license may be ok), your child, the other parent of your child, and all together go to the nearest passport agency. The all together part of the process is important: if your partner can't be there, you'll need more paperwork ahead of time, and baby must be with you.
[ ... ]
I have been living in different countries for the last 10 years. Although I can get in touch with friends and family using gtalk, skype, or you name it, having an extremely cheap phone line to receive or make calls on can come in handy.
Given my love for technology, trying out VoIP (or voice over IP, or phone over the internet), seemed like the next logical step.
There are 2 things you need to do to get started with VoIP:
-
Find a VoIP provider, what people in the industry refer to as an ITSP (aka Internet Telephony Service Provider). A fancy name for a company with tons of phone lines and good internet connectivity willing to turn phone traffic on good old phone networks (called PTSN, or public switched telephone network) into internet packets.
-
Get a VoIP phone, eg, any sort of "telephone like thingy" that is able to route and receive calls over the internet using the VoIP protocol. We will talk more about this later, but what I mean by "telephone like thingy" can take many different shapes and colors: it can be an iphone or android app installed on your smart phone, a black box with a telephone plug on one side, and an internet plug on the other side (generally referred to as ATA - Analog Telephone Adapter), or something that pretty much looks like a phone from the 60s but happens to have an ethernet plug rather than a telephone one.
[ ... ]
In a previous article we talked about how to use ssh keys and an ssh agent.
Unfortunately for you, we promised a follow up to talk about the security implications of using such an agent. So, here we are.
If you are the impatient kind of reader, here is a a few rules of thumb you should follow:
-
Never ever copy your private keys on a computer somebody else has root on. If you do, you just shared your keys with that person.
If you also use that key from that computer (why would you copy it, otherwise?), you also shared your passphrase. I generally go further and only keep my private keys on my personal laptop, and start all ssh sessions from there.
-
Never ever run an
ssh-agenton a computer somebody else has root on.Just as with the keys, I generally don't run ssh-agents anywhere but my laptop. And when I say "has root on", consider that you are both trusting that person to not abuse his privileges, and to do a good job at keeping the system safe, up to date, and without other visitors.
[ ... ]
If you work a lot on linux and use ssh often, you quickly
realize that typing your password every time you connect to a remote
host gets annoying.
Not only that, it is not the best solution in terms of security either:
- Every time you type a password, a snooper has an extra chance to see it.
- Every host you ssh to with which you use your password, well, has to know your password. Or a hash of your password. In any case, you probably have typed your password on that host once or twice in your life (even if just for passwd, for example).
- If you are victim of a Man In The Middle attack, your password may get stolen. Sure, you can verify the fingerprint of every host you connect to, and disable authentication without challenge and response in your ssh config. But what if there was a way you didn't have to do that?
This is where key authentication comes into play: instead of using a password
to log in a remote host, you can use a pair of keys, and well, ssh-agent.
[ ... ]
Down with the spinning disks! And hail the SSDs!
That's about what happened the last time I upgraded my laptop. SSDs were just so much faster, energy efficient, and quieter that I couldn't stand the thought of remaining loyal to the trustful spinning disks.
So... I just said goodbye to a few hundred dollars to welcome a Corsair Force GS on my laptop, and been happy ever after.
Or so I thought. Back to the hard reality: last week my linux kernel started spewing read errors at my face, and here is a tale of what I had to do in order to bring my SSD back to life.
It all started on a Friday morning with me running an apt-get install randomapp on my system.
The command failed with an error similar to:
# apt-get install random-app-whatever-it-was ... (Reading database ... dpkg: error processing whatever.deb (--install): dpkg: unrecoverable fatal error, aborting: reading files list for package 'libglib2.0-data': Input/output error E: Sub-process /usr/bin/dpkg returned an error code (2)
where libglib.20-data had nothing to do with what I was trying to install.
[ ... ]
Let's say you want to add a search box to your web site to find words within your published content. Or let's say you want to display a list of articles published on your blog, together with snippets of what the article looks like, or a short summary.
In both cases you probably have an .html page or some content from which you want to generate a snippet, just like on this blog: if you visit http://rabexc.org, you can see all articles published recently. Not the whole article, just a short summary of each.
Or if you look to the right of this page, you can see snippets of articles in the same category as this one.
Turns out that generating those snippets in python using flask and basic python
library is extremely easy.
So, here are a few ways to do it...
Before starting to talk about python, I should mention that doing this in javascript should be extremely easy and straightforward. In facts, you can find many sites that load entire articles and then magically hide portions of it using javascript.
[ ... ]
Have you ever had to pay extra fees to carry oversize luggage? Flown somewhere, ended up buying so many things that they did not fit your suitcase anymore?
Here's a nifty trick we used in our last trip to Europe which allowed us to carry much more than we believed we could at no extra charge.
First: make sure to read the allowances for carry on and check in baggage on your ticket. Make sure you understand them fully, and if unsure, call your airline.
In our case, me, my wife, and baby were traveling on a Swiss Airlines fligth, and our ticket allowed us to bring for free:
- 2 Carry on bags.
- 3 Checked in bags.
The checked in bags were limited in weight and length:
- 23 Kg (~50 lbs) at most.
- 158 cm (~62 inches) of linear length, where linear length is the sum of the width, depth, and height of your suitcase.
In our case, we discovered that:
-
The large suitcases we used weighted about ~7 Kg (~15 lbs) empty. With no clothes, no items whatsover, the suitcase itself used up ~30% of our allowance!!
-
The small suitcases weighted ~5 Kg empty, or about ~21% of our allowance.
[ ... ]
With my last laptop upgrade I started using awesome as a Window Manager.
I wasn't sure of the choice at first: I have never liked graphical interfaces,
and the thought of having to write lua code to get my GUI to provide even
basic functionalities wasn't very appealing to me.
However, I have largely enjoyed the process so far: even complex changes are relatively easy to make, while the customizability has improved my productivity while making the interface more enjoyable for me to use.
The switch, however, has forced me to change several things in my
setup. Among others, I ended up abandoning xscreensaver for i3lock and
xautolock, while changing a few things on my system to better integrate with
the new environment.
In this article, you will find:
-
A description of how to use
xautolocktogether withi3lockto automatically lock your screen after X minutes of inactivity and when the laptop goes to sleep via ACPI. -
My own recipe to display the battery status on the top bar of Awesome. This is very similar to existing suggestions on the Awesome wiki, except there is support for displaying the status of multiple batteries at the same time. Which, for how rare this may sound, is something supported on my laptop which I regularly use (x230 with 19+ cell slice battery).
[ ... ]
Let's say you want to make the directory /opt/test on your desktop machine
visible to a virtual machine you are running with libvirt.
All you have to do is:
-
virsh edit myvmname, edit the XML of the VM to have something like:<domains ...> ... <devices ...> <filesystem type='mount' accessmode='passthrough'> <source dir='/opt/test'/> <target dir='testlabel'/> </filesystem> </devices> </domains>
where
/opt/testis the path you want to share with the VM, andtestlabelis just a mnemonic of your choice.Make sure to set
accessmodeto something reasonable for your use case. According to the libvirt documentation, you can use:- mapped
- To have files created and accessed as the user running kvm/qemu. Uses extended attributes to store the original user credentials.
- passthrough
- To have files created and accessed as the user within kvm/qemu.
[ ... ]
All the libvirt related commands, like virsh, virt-viewer or virt-install take
a connect URI as parameter. The connect URI can be thought as specifying which set of
virtual machines you want to control with that command, which physical machine to control,
and how.
For example, I can use a command like:
virsh -c "xen+ssh://admin@corp.myoffice.net" start web-server
to start the web-server virtual machine on the xen cluster running at myoffice.net,
by connecting as admin via ssh to the corresponding server.
If you don't specify any connect URI to virsh (or any other libvirt related command), by
default libvirt will try to start a VM running as your username on your local machine
(eg, qemu:///session). This unless you are running as root, in which case libvirt will try to
run the image as a system image, not tied to any specific user (eg, qemu:///system).
I generally run most of my VMs as system VMs, and systematically forget to specify which connect
URI to use to commands like virsh or virt-install. What is more annoying is that some of
those commands take the URI as -c while others as -C.
[ ... ]
While traveling, I have been asked a few times by security agents at airports to turn on my laptop, and well, show them it did work, and looked like a real computer.
Although they never searched the content and nothing bad ever happend, every time I cross the border or go through security I am worried about what might happen, especially given recent stories of people being searched and their laptops taken away for further inspection.
The fact I use full disk encryption does not help: if I was asked to boot, my choice would be to either enter the password and login, thus disclosing most of the content of the disk, or refuse and probably have my laptop taken away for further inspection.
So.. for the first time in 10 years, I decided to keep Windows on my personal laptop. Even more, leave it as the default operating system in GRUB, and well, not show up GRUB at all during boot.
Not because I think it is safer this way, but just to create as little pretexts or excuses for anyone to further poke at my laptop, in case I need to show it or they need to inspect it.
[ ... ]
I am writing a small python script to keep track of various events and messages. It uses a flat file as an index, each record being of the same size and containing details about each message.
This file can get large, in the order of several hundreds of megabytes. The python code is trivial, given that each record is exactly the same size, but what is the fastest way to access and use that index file?
With python (or any programming language, for what is worth), I have plenty of ways to read a file:
- I can just rely on
readandio.readin python having perfectly good buffering, and justread(orio.read) a record at a time. - I can read it in one go, and then operate in memory (eg, a single
readin a string, followed by using offsets within the string). - I can do my own buffering, read a large chunk at a time, and then operate
on each chunk as a set of records (eg, multiple
readof some multiple of the size of the record, followed by using offsets within each chunk). - I can use fancier libraries that allow me to
mmapor use some other crazy approach.
[ ... ]
Some say that clothes smell and look better when dried with sunlight in the summer breeze.
I can certainly state that if you have to pay to use a dryer, it is much cheaper to use sunlight, and line dry. And really, it's not that much more work.
The only annoying part where we live is the wind: yes, it gets the clothes to dry faster, but it also gets them to fall off the line, and on the grass of our backyard.
If we had a normal rack to dry clothes, this would not be a big deal: humanity has long figured out how to get clothes not to fall off clothes racks. There are such mechanical devices like clothespins that can be easily purchased and used.
The tricky part in our case is that we have some sort of line going from one building to another that we use to hang clothes on. This line is exposed to the weather, gets dirty to the point it is really hard to clean, and we generally don't want to put our clothes directly on it. Instead, we use hangers.

This is where the wind comes into play: it's not that hard for the wind to knock off our clothes, and get them to the ground, and well, dirty.
[ ... ]
Just a few days ago I realized that the Raspberry PI I use to control my irrigation system was dead. Could not get to the web interface, pings would time out, could not ssh into it.
The first thing I tried was a simple reboot. The raspberry is in a black box in my backyard, maybe the hot summer days were... too hot? I have a cron job that shuts it down if the temperature goes above 70 degrees. Or maybe the shady wireless card and its driver stopped working? I have another cron job to restart it, so this seems less likely.
So.. I reboot it by phyiscally unplugging it, but still nothing happens. The red led on the board, next to the ethernet plug is on, which means it is getting power. The green led next to it flashes only once. By reading online, this led can flash to report an error, or to indicate that the memory card is being read.
There is no error corresponding to one, single, flash, so I assume it means that it tried to read the flash, and somehow failed. It is supposed to be booting now, so I would expect much more activity from the memory card.
[ ... ]
When it comes to HTML, CSS, and graphical formatting, I feel like a daft noob.
Even achieving the most basic formatting seems to take longer than it should. Giving up on reasonable compromises is often more appealing to me than figuring out the right way to achieve the goal.
Anyway, tonight I am overjoyed! I wanted to have a <pre> block, with code that:
- had an horizontal scroll bar.
- but only when there are lines too long.
- and well, long lines did not wrap.
I first fidgeted with the white-space property in the attribute, which has a nowrap value, and various other ones. None of them seemed to do what I wanted, the only valid value to preserve white spacing was pre.
overflow-x: auto was easy to find. It would do the right thing except... the text was wrapping, so the scroll bar never showed up.
It took me a while to discover that a word-wrap: normal would do exactly what I wanted.
So, here is the final CSS:
pre { word-wrap: normal; overflow-x: auto; white-space: pre; }
And here is what it looks like rendered:
This is a really really really really really really really really really really really really really really really really really really really really really really really long line
It's amazing how happiness at times can come from very little things.
[ ... ]
I've always liked text consoles more than graphical ones. This at least until some time in 2005, when I realized I was spending a large chunk of my time in front of a browser, and elinks, lynx, links and friends did not seem that attractive anymore.
Nonetheless, I've kept things simple: at first I started X manually, with startx, on a need by need basis. I used ion (yes! ion) for a while, until it stopped working during some upgrade. Than I decided it was time to boot in a graphical interface, and started using slim. Despite some quirks, I've been happy since.
In terms of window managers, I really don't like personalizing or tweaking my graphical environment. I see it as a simple tool that should be zero overhead, require no maintenance, and not get in the way of what I want to do with a computer. I don't want to learn which buttons to click on, how to do transparency, which icons mean what, or where the settings I am looking for were moved to in the latest version.
[ ... ]
If you like hacking and have a few machines you use for development, chances are your system has become at least once in your lifetime a giant meatball of services running for who knows what reason, and your PATH is clogged with half finished scripts and tools you don't even remember what they are for.
If this never happened to you, don't worry: it will happen, one day or another.
My first approach at sorting this mess out were chroots. The idea was simple: always develop on my laptop, but create a self contained environment for each project. In each such environment, install all the needed tools, libraries, services, anything that was needed for my crazy experiments.
This was fun for a while and worked quite well: I became good friend with with rsync, debootstrap, mount --rbind and sometimes even pivot_root, and I was happy.
Until, well, I run into the limitations of chroots: can't really simulate networking, can't run two processes on port 80, can't run different kernels (or OSes), and don't really help if you need to work on something boot related or that has to do with userspace and kernel interactions.
[ ... ]
Just a few days ago I finally got a new server to replace a good old friend of mine which has been keeping my data safe since 2005. I was literally dying to get it up and running and move my data over when I realized it had been 8 years since I last setup dmcrypt on a server I only had ssh access to, and had no idea of what best current practices are.
So, let me start first by describing the environment. Like my previous server, this new machine is setup in a datacenter somewhere in Europe. I don't have any physical access to this machine, I can only ssh into it. I don't have a serial port I can connect to over the network, I don't have IPMI, nor something like intel kvm, but I really want to keep my data encrypted.
Having a laptop or desktop with your whole disk encrypted is pretty straightforward with modern linux systems. Your distro will boot up, kernel will be started, your scripts in the initrd will detect the encrypted partition, stop the boot process, ask you for a passphrase, decrypt your disk, and happily continue with the boot process.
[ ... ]
Let's say you have a CSS with a few thousand selectors and many many rules. Let's say you want to eliminate the unused rules, how do you do that?
I spent about an hour looking online for some tool that would easily clean up CSS files. I've ended up trying a few browser extensions:
-
CSS Remove and combine, for chrome, did not work for me. It would only parse the very first web site in my browser window, and seemed to refuse
file:///urls. I later discovered thatchromenatively supports this feature: just go indeveloper tools(ctrl + shift + i), click theauditstab, clickrun, and you will find a drop down with the list of unused rules in your CSS. -
Dust-me Selectors, for firefox, worked like a charm: it correctly identified all the unused selectors.
In both cases, however, the list was huge, I had thousands of unused selectors. I was really not looking forward to go through my CSS by hand, considering also that many styles had multiple selectors, and I could only remove the unused ones.
[ ... ]
Let's say you have a regression test or fuzzy testing suite that relies on generating a random set of operations, and verifying their results (like ldap-torture).
You want this set operations to be reproducible, so if you find a bug, you can easily get to the exact same conditions that triggered it.
There are many ways to do this, but one simple way is to use one of many pseudo random generators, one that given the same starting seed generates the same sequence of random numbers. Example?
Let's look at perl:
# Seed the random number generator. srand($seed); # Generate 100 random numbers. for (my $count = 0; $count < 100; $count++) { print rand() . "\n"; }
Given the same $seed, the sequence of random numbers will always be the same. Not surprising, right?
Now, let's go back to our original problem: you want your test to be reproducible, but still be random. Something you can do is get rid of $seed, and just call srand(). srand will return the seed generated, that you can helpfully print on the screen and reuse if you need to. The final code would look like:
if ($seed) { # Use an existing seed to reproduce a failing test. srand($seed); } else { # Let srand pick a seed to start a newly randomized test. $seed = srand(); } print "TO REPRODUCE TEST, USE SEED: " . $seed . "\n";
Now, where is the problem? Well, the problem is that before perl 5.14 (~2011, in case you are wondering), srand() did not return the seed it set. Just doing $seed = srand() did not work.
[ ... ]
While trying to get ldap torture back in shape, I had to learn again how to get slapd up and running with a reasonable configs. Here's a few things I had long forgotten and I have learned this morning:
- The order of the statements in
slapd.confis relevant. Don't be naive, even though the config looks like a normal key value store, some keys can be repeated multiple times (like backend, or database), and can only appear before / after other statements. - My good old example slapd.conf file, no longer worked with
slapd. Some of it is because the setup is just different, some of it because I probably had a few errors to being with, some of it is because a few statements moved around or are no longer valid. See the changes I had to make. -
Recent versions of
slapdsupport having configs in the database itself, or at least represented in ldiff format and within the tree. Many distros shipslapdwith the new format. To convert from the old format to the new one, you can use:slapd -f slapd.conf -F /etc/ldap/slapd.d
-
I had long forgotten how quiet
slapdcan be, even when things go wrong. Looking in/var/log/syslogmight often not be enough. In facts, my database was invalid, configs had error, and there was very little indication of the fact that when I started slapd, it was sitting there idle because it couldn't really start. To debug errors, I ended up running it with:slapd -d Any -f slapd.conf
-
slapdwill not create the initial database by itself. To do so, I had to use:/usr/sbin/slapcat -f slapd.conf < base.ldiff
with
base.ldiffbeing something like this.
[ ... ]
Have you ever been lost in conversations or threads about one or the other file system? which one is faster? which one is slower? is that feature stable? which file system to use for this or that payload?
I was recently surprised by seeing ext4 as the default file system on a new linux installation. Yes, I know, ext4 has been around for a good while, and it does offer some pretty nifty features. But when it comes to my personal laptop and my data, well, I must confess switching to something newer always sends shrives down my back.
Better performance? Are you sure it's really that important? I'm lucky enough that most of my coding & browsing can fit in RAM. And if I have to recompile the kernel, I can wait that extra minute. Is the additional slowness actually impacting your user experience? and productivity?
Larger files? Never had to store anything that ext2 could not support. Even with a 4Gb file limit, I've only rarely had problems (no, I don't use FAT32, but when dmcrypt/ecryptfs/encfs and friends did not exist, I used for years the good old CFS, which turned out to have a 2Gb file size limit).
Less fragmentation? More contiguous blocks? C'mon, how often have you had to worry about the fragmentation of your ext2 file system on your laptop?
What I generally worry about is the safety of my data. I want to be freaking sure that if I lose electric power, forget my laptop in suspend mode or my horrible wireless driver causes a kernel panic I don't lose any data. I don't want no freaking bug in the filesystem to cause any data loss or inconsistency. And of course, I want a good toolset to recover data in case the worst happens (fsck, debug.*fs, recovery tools, ...).
[ ... ]
Back in 2004 I was playing a lot with OpenLDAP. Getting it to run reliably turned out more challenging than I had originally planned for:
- BerkeleyDB performance was terrible if the proper tunings were not provided. Nowhere in the docs was mentioned that this was necessary. The way to do it was to drop a
DB_CONFIGfile in the top level directory of the database. Not a feature of openldap, rather a feature of BerkeleyDB. - Not only performance would be terrible, but even the latest BerkeleyDB versions at the time had a bug (feature?) by which with the indexes used by openldap the database would deadlock if certain parts of the index did not fit in memory. I don't remember the details of the problem, it's been too long, but I do remember it was painful, and ended up submitting changes to the openldap package in debian to make sure this was mentioned in the documentation, and that a reasonable default would be provided.
- At the time, OpenLDAP supported two kind of backends:
BDB, andHDB, both based on BerkeleyDB. The first, older, did not support operations like 'movedn', which had been standardized in the LDAP protocol for a while, and a few other features thatHDBhad.HDBthough, was marked as experimental. During our use, we found several bugs.
[ ... ]